什么是display topic
display topic 是谷歌展示广告用来聚焦对某个主体感兴趣的客户的,就像公司热衷于某些客户,客户也会对某些主题感兴趣。
关于操作和报告
可以在adgroup级别添加google提供的主题列表中一个或者多个。可以通过display topic performance report查看其成效。
display topic 是谷歌展示广告用来聚焦对某个主体感兴趣的客户的,就像公司热衷于某些客户,客户也会对某些主题感兴趣。
可以在adgroup级别添加google提供的主题列表中一个或者多个。可以通过display topic performance report查看其成效。
百度,搜索解决思路、方案并组织成自己的表达和架构图(可以短期内解决)
百度面试公司尤其是部门的业务特点,现有技术,并设计方案。
不少同学,他们的项目其实并不高端,甚至是有点low。但是呢,人家凭借自己精心的准备,加上一些面试技巧,巧妙的让自己的项目脱胎换骨,瞬间变得高大上
突击准备,你肯定没有大把时间来付诸实践,但是你一定要自己思考,同时百度一下国内一线互联网公司的技术架构,他们使用了哪些高大上的技术,对于某个技术难点采用了什么技术方案。
然后在面试的时候,可以对面试官阐述一下你对这个项目一些问题的思考,以及技术方案、架构如何来设计,这样设计可以解决什么技术问题,有没有更好的方案选择。
是那句话,做,总比不做强。你对自己的项目思考了很多的技术方案,这样和面试官总还有一些技术上的交流和探讨的东西。你的项目也不至于说充满了各种CRUD,毫无亮点可言
FLINK_HOME/conf/log4j-cli.properties在本地模式中,比如在IDE中运行你的应用,你可以像往常一样配置log4j,比如在classpath中生成一个可用的log4j.properties。一个简单的方式就是在maven项目src/main/resources目录下创建log4j.properties。如下例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25log4j.rootLogger=INFO, console
# patterns:
# d = date
# c = class
# F = file
# p = priority (INFO, WARN, etc)
# x = NDC (nested diagnostic context) associated with the thread that generated the logging event
# m = message
# Log all infos in the console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{dd/MM/yyyy HH:mm:ss.SSS} %5p [%-10c] %m%n
# Log all infos in flink-app.log
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.file=flink-app.log
log4j.appender.file.append=false
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{dd/MM/yyyy HH:mm:ss.SSS} %5p [%-10c] %m%n
# suppress info messages from flink
log4j.logger.org.apache.flink=WARN
在独立模式下,实际使用的配置文件不是jar包里的那个。这是因为Flink有自己的配置文件,这些文件优先于您自己的配置文件。
默认文件: Flink附带以下默认属性文件
log4j-cli.properties: 由Flink命令行客户端使用(例如flink run)(不是在集群上执行的代码)log4j-yarn-session.properties: 启动YARN会话时由Flink命令行客户端使用(yarn-session.sh)log4j.properties: JobManager / Taskmanager日志(独立和YARN)请注意,${log.file}默认为flink/log。可以通过设置env.log.dir在flink-conf.yaml中覆盖它。env.log.dir定义保存Flink日志的目录。它必须是一条绝对路径。
Log location: 日志是本地的,即它们是在运行JobManager/Taskmanager(s)的机器中生成的。
Yarn: 在Yarn上运行Flink时,您必须依赖Hadoop YARN的日志记录功能。最有用的功能是YARN日志聚合。要启用它,请在yarn-site.xml文件中将yarn.log-aggregation-enable属性设置为true。启用后,您可以使用检索(失败的)YARN会话的所有日志文件yarn logs -applicationId <application ID>
不幸的是,日志仅在会话停止运行后可用,例如在失败后。
随着无处不在的传感器网络和智能设备不断收集越来越多的数据,我们面临着近乎实时地分析不断增长的数据流的挑战。 能够快速响应不断变化的趋势或提供最新的商业智能可能是公司成功或失败的决定性因素。 实时处理中的关键问题是检测数据流中的事件模式。
复杂事件处理(CEP)恰好解决了连续传入事件与模式匹配的问题。 匹配的结果通常是从输入事件派生的复杂事件。 与对存储数据执行查询的传统DBMS相比,CEP在存储的查询上执行数据。 可以立即丢弃与查询无关的所有数据。 考虑到CEP查询应用于潜在的无限数据流,这种方法的优势是显而易见的。 此外,输入被立即处理。 一旦系统看到匹配序列的所有事件,结果就会立即发出。 这有效地带来了CEP的实时分析能力。
因此,CEP的处理范例引起了人们的极大兴趣,并在各种用例中得到了应用。 最值得注意的是,CEP现在用于诸如股票市场趋势和信用卡欺诈检测等金融应用。 此外,它用于基于RFID的跟踪和监控,例如,用于检测仓库中的物品未被正确检出的盗窃。 通过指定可疑用户行为的模式,CEP还可用于检测网络入侵。
Apache Flink具有真正的流媒体特性以及低延迟和高吞吐量流处理功能,非常适合CEP工作负载。 因此,Flink社区已经推出了Flink 1.0的新CEP库的第一个版本。 在本博文的其余部分,我们将介绍Flink的CEP库,并通过监控数据中心的示例说明其易用性。
监控和警报生成数据中心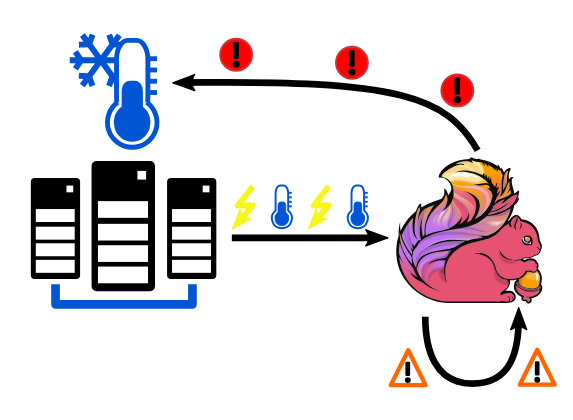
假设我们有一个带有多个机架的数据中心。 对于每个机架,都会监控功耗和温度。 无论何时发生这种测量,分别产生新的功率或温度事件。 基于此监控事件流,我们希望检测即将过热的机架,并动态调整其工作负载和冷却。
对于这种情况,我们使用两阶段方法。 首先,我们监测温度事件。 每当我们看到温度超过阈值的两个连续事件时,我们就会产生一个温度警告,其中包含当前的平均温度。 温度警告不一定表示机架即将过热。 但是,每当我们看到连续两次警告温度升高时,我们就会发出此机架的警报。 然后,该警报可以导致对冷却机架的对策。
首先,我们定义传入监视事件流的消息。 每条监控消息都包含其原始机架ID。 温度事件还包含当前温度,功耗事件包含当前电压。 我们将事件建模为POJO:1
2
3
4
5
6
7
8
9
10
11
12
13
14public abstract class MonitoringEvent {
private int rackID;
...
}
public class TemperatureEvent extends MonitoringEvent {
private double temperature;
...
}
public class PowerEvent extends MonitoringEvent {
private double voltage;
...
}
现在我们可以使用Flink的一个连接器(例如Kafka,RabbitMQ等)来摄取监视事件流。 这将为我们提供一个DataStream<MonitoringEvent> inputEventStream,我们将其用作Flink的CEP算子的输入。 但首先,我们必须定义事件模式以检测温度警告。 CEP库提供了一个直观的Pattern API,可以轻松定义这些复杂的模式。
每个模式都由一系列事件组成,这些事件可以指定可选的过滤条件。 模式始终以第一个事件开始,我们将为其指定名称“First Event”1
Pattern.<MonitoringEvent>begin("First Event");
此模式将匹配每个监视事件。 由于我们只对温度高于阈值的TemperatureEvents感兴趣,我们必须添加一个额外的子类型约束和一个where子句1
2
3Pattern.<MonitoringEvent>begin("First Event")
.subtype(TemperatureEvent.class)
.where(evt -> evt.getTemperature() >= TEMPERATURE_THRESHOLD);
如前所述,当且仅当我们在温度过高的同一机架上看到两个连续的TemperatureEvent时,我们才想生成温度警告。 Pattern API提供下一个调用,允许我们向模式添加新事件。 此事件必须直接跟随第一个匹配事件,以便整个模式匹配1
2
3
4
5
6
7Pattern<MonitoringEvent, ?> warningPattern = Pattern.<MonitoringEvent>begin("First Event")
.subtype(TemperatureEvent.class)
.where(evt -> evt.getTemperature() >= TEMPERATURE_THRESHOLD)
.next("Second Event")
.subtype(TemperatureEvent.class)
.where(evt -> evt.getTemperature() >= TEMPERATURE_THRESHOLD)
.within(Time.seconds(10));
最终模式定义还包含内部API调用,该调用定义了两个连续的TemperatureEvent必须在10秒的时间间隔内发生以使模式匹配。 根据时间特性设置,这可以是处理,摄取或事件时间。
定义了事件模式后,我们现在可以将它应用于inputEventStream1
2
3PatternStream<MonitoringEvent> tempPatternStream = CEP.pattern(
inputEventStream.keyBy("rackID"),
warningPattern);
由于我们希望单独为每个机架生成警告,因此我们通过“rackID” POJO 字段键入(keyBy)输入事件流。 这会强制我们模式的匹配事件都具有相同的机架ID
PatternStream<MonitoringEvent>使我们能够访问成功匹配的事件序列。 可以使用select API调用访问它们。 select API调用采用PatternSelectFunction,为每个匹配的事件序列调用。 事件序列以Map<String,MonitoringEvent>的形式提供,其中每个MonitoringEvent由其指定的事件名称标识。 我们的模式选择函数为每个匹配模式生成一个TemperatureWarning事件
1 | public class TemperatureWarning { |
现在我们从初始监视事件流生成了一个新的复杂事件流DataStream<TemperatureWarning>警告。 此复杂事件流可再次用作另一轮复杂事件处理的输入。 每当我们看到温度升高的同一机架连续两次温度警报时,我们就会使用TemperatureWarnings生成TemperatureAlerts。 TemperatureAlerts具有以下定义:1
2
3
4public class TemperatureAlert {
private int rackID;
...
}
首先,我们必须定义警报事件模式:1
2
3Pattern<TemperatureWarning, ?> alertPattern = Pattern.<TemperatureWarning>begin("First Event")
.next("Second Event")
.within(Time.seconds(20));
这个定义说我们希望在20秒内看到两个温度警报。 第一个事件的名称为“First Event”,第二个连续的事件的名称为“Second Event”。 单个事件没有分配where子句,因为我们需要访问这两个事件以确定温度是否在增加。 因此,我们在select子句中应用过滤条件。 但首先,我们再次获得一个PatternStream。1
2
3PatternStream<TemperatureWarning> alertPatternStream = CEP.pattern(
warnings.keyBy("rackID"),
alertPattern);
同样,我们通过“rackID”键入(keyBy)警告输入流,以便我们单独为每个机架生成警报。 接下来,我们应用flatSelect方法,该方法将允许我们访问匹配的事件序列,并允许我们输出任意数量的复杂事件。 因此,当且仅当温度升高时,我们才会生成TemperatureAlert1
2
3
4
5
6
7
8
9
10DataStream<TemperatureAlert> alerts = alertPatternStream.flatSelect(
(Map<String, List<TemperatureWarning>> pattern, Collector<TemperatureAlert> out) -> {
TemperatureWarning first = pattern.get("first").get(0);
TemperatureWarning second = pattern.get("second").get(0);
if (first.getAverageTemperature() < second.getAverageTemperature()) {
out.collect(new TemperatureAlert(first.getRackID()));
}
},
TypeInformation.of(TemperatureAlert.class));
DataStream<TemperatureAlert>警报是每个机架的温度警报的数据流。 基于这些警报,我们现在可以调整过热架的工作负载或冷却。
可以在此repository中找到所提供示例的完整源代码以及生成随机监视事件的示例数据源。
在这篇博文中,我们已经看到使用Flink的CEP库推理事件流是多么容易。 使用数据中心的监控和警报生成示例,我们实施了一个简短的程序,当机架即将过热并可能发生故障时通知我们。
在未来,Flink社区将进一步扩展CEP库的功能和表现力。 路线图上的下一步是支持正则表达式模式规范,包括Kleene star,下限和上限以及否定。 此外,计划允许where子句访问先前匹配的事件的字段。 此功能将允许尽早修剪无意义的事件序列。
注意:示例代码需要Flink 1.6.1或更高版本。
许多Apache Flink®用户正在构建警报或异常检测应用程序,ING和Mux是最近Flink Forward会议的两个例子。
今天,我们将重点介绍BetterCloud的工作,他们了解到,只有当新创建的警报应用于未来事件以及历史事件时,动态警报工具才真正对其客户有用。
在这篇客座文章中,我们将详细讨论BetterCloud如何使用Apache Flink为其警报提供动力,以及他们如何以高效的方式应对新创建的警报应用于历史事件数据的挑战。
这篇文章改编自2017年Flink Forward旧金山的BetterCloud会议。你可以在这里找到他们演讲的录音和幻灯片。
BetterCloud是一个多SaaS管理平台,可简化运营当今现代工作场所的IT专业人员的工作。 近年来,随着各种规模的公司依赖各种SaaS应用程序来运营其业务,这个世界变得更加复杂。
该平台作为IT的“任务控制”:用于管理公司内部使用的许多不同SaaS应用程序的单一控制台,例如Slack,G Suite,Salesforce和Dropbox。 BetterCloud允许其用户根据不同SaaS产品中的用户活动创建警报并执行自动策略。 例如,如果用户开始将其工作电子邮件转发到其个人Gmail帐户 - 提出潜在的安全问题 - IT或安全团队可以在BetterCloud中创建警报,自动阻止进一步转发,并向该个人发送通知,提醒他们公司政策。 BetterCloud还可以跨应用程序自动化复杂流程,例如入职或离职员工帐户(仅限G Suite,平均离职流程包含28个独特步骤)
BetterCloud提供了一个可供所有客户使用的“全局”警报库,它还使客户能够配置自定义警报。当客户创建BetterCloud警报时,它可以应用于未来事件以及历史事件。启用此自定义警报功能(可应用于未来事件和历史事件)为BetterCloud工程团队提出了一个非常重要的技术问题,在本文中,我们将详细介绍如何使用Apache Flink构建我们的警报系统来处理 未来和历史事件同时:

在警报项目开始时,我们的团队很快了解到事件流处理模型最适合我们的用例,具体而言,它比摄取(ingest)和查询模型更适合我们的警报应用程序。
由于大量的冗余处理,摄取和查询相对较慢且低效。我们已经提到低延迟对于像我们这样的警报系统很重要,而且这是摄取和查询模型无法做到的。最后,摄取和查询更多地关注状态而不是状态转换,而状态转换对我们来说很最重要。
每天由BetterCloud平台处理的数亿个事件已经通过Apache Kafka流式传输给我们(我们的数据提取团队在前期工作方面做得非常好),因此事件流处理模型对我们来说很简单
在选择流处理器时,BetterCloud不仅仅是凭空或者掷硬币选择Flink。我们根据一组评估标准评估了四种不同的流处理解决方案。我们选择选定了Flink,因为其充满活力的社区,商业支持的可用性以及实现exactly once处理的能力。
第二个关键设计决策:在流程的早期,我们认为规则引擎比硬编码规则更有价值。硬编码规则难以维护,缺乏灵活性,并且对于工程团队来说并不是很有趣。此外,我们的客户需要能够根据他们关心的事件自定义警报。
我们的团队已经将Avro或JSON作化为序列化格式的标准,因此我们选择了Jayway的JsonPath作为规则引擎。JsonPath对离散的JSON文档执行查询,它还提供了一种非常简单的方法来围绕查询包装非技术用户界面。在线上实际运行新查询之前,我们的用户也可以先测试新查询是否按预期工作。
JsonPath将文档解析为树,并使用熟悉的点表示法遍历树。它还提供索引和JavaScript运算符的子集(例如,数组的长度)。它支持的查询相当复杂。
结果是我们的最终用户可以在BetterCloud平台内创建自己的警报,并根据自定义事件的某些组合进行触发。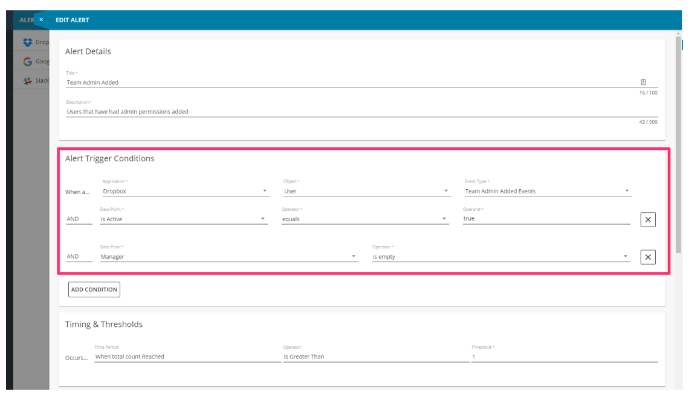
用户添加新警报规则后,将其作为控制事件提交。我们的团队非常自由地使用控制事件,以便我们的Flink工作动态(基本上说:“嘿,这是我们希望您看到的新事物”),并且当新事件通过实时事件流时,我们能够 根据新增的规则评估它们。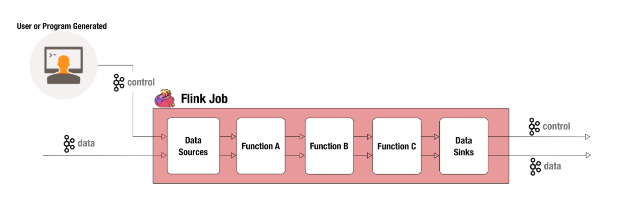
在我们的大部分Flink工作中,第一个功能是CoFlatMap的变体。当一起滚动时,我们最终得到2个Kafka源:一个用于控制事件,一个用于实时数据。两者都流入过滤功能,该功能维护由控制事件发送的警报配置。我们检查客户是否为他们创建的事件类型配置了任何警报,然后我们将该事件与所有可能匹配的警报相结合。
接下来,事件将转发到限定符函数,该函数负责对警报配置执行JsonPath评估。如果事件与警报配置匹配,则将其转发到计数器函数,然后将该事件发送到输出流。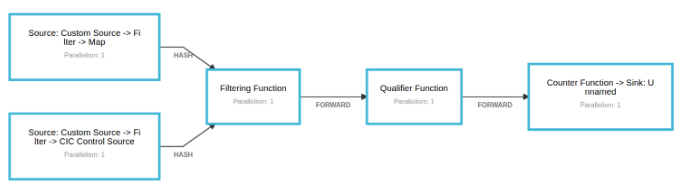
现在,让我们来看看我们的一个Flink工作的简化版本。如果你想仔细看看我们在这篇文章中提到的代码,它可以在Github上找到。
首先,这是我们的每个事件类型的样子。客户事件(我们的实时事件流)具有客户ID和有效负载,它是JSON字符串。控制事件具有客户ID,警报ID以及许多其他字段,包括引导客户ID,我们稍后会介绍。 这在将新创建的规则应用于历史数据方面发挥了作用。1
2
3case class CustomerEvent(customerId: UUID, payload: String)
case class ControlEvent(customerId: UUID, alertId: UUID, alertName: String, alertDescription: String, threshold: Int, jsonPath: String, bootstrapCustomerId: UUID)
如前所述,我们有一个事件流源,它以客户ID为键,以确保在单个Flink任务管理器上维护单个客户的所有计数。您将看到我们过滤掉与模式不匹配的事件。1
2
3
4val eventStream = env.addSource(new FlinkKafkaConsumer09("events", new CustomerEventSchema(), properties))
.filter(x => x.isDefined)
.map(x => x.get)
.keyBy((ce: CustomerEvent) => { ce.customerId } )
还有一个控制流源:
1 | val controlStream = env.addSource(new FlinkKafkaConsumer09("controls", new ControlEventSchema(), properties)) |
BetterCloud中的一些规则是全局规则,这意味着它们可供所有客户使用。那些,我们向所有task manager广播如下:1
val globalControlStream = controlStream.select("global").broadcast
其他规则是特定于客户的,因此使用我们在实时事件流中所期望的相同客户ID进行键控。1
2val specificControlStream = controlStream.select("specific")
.keyBy((ce: ControlEvent) => { ce.customerId })
然后,我们将事件流连接到全局和特定控制流的联合:1
2val filterStream = globalControlStream.union(specificControlStream)
.connect(eventStream)
接下来,事件进入CoFlatMap。FlatMap 1将控件事件添加到本地状态的列表中。如果现有规则有更新,我们也可以在此处进行更改。FlatMap 2接收实时客户事件并检查是否存在与该客户ID匹配的任何规则配置。如果匹配,则将事件与所有匹配的控制事件一起输出为单个过滤事件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class FilterFunction() extends RichCoFlatMapFunction[ControlEvent, CustomerEvent, FilteredEvent] {
var configs = new mutable.ListBuffer[ControlEvent]()
override def flatMap1(value: ControlEvent, out: Collector[FilteredEvent]): Unit = {
configs = configs.filter(x => (x.customerId != value.customerId) && (x.alertId != value.alertId))
configs.append(value)
}
override def flatMap2(value: CustomerEvent, out: Collector[FilteredEvent]): Unit = {
val eventConfigs = configs.filter(x => (x.customerId == x.customerId) || (x.customerId == Constants.GLOBAL_CUSTOMER_ID))
if (eventConfigs.size > 0) {
out.collect(FilteredEvent(value, eventConfigs.toList))
}
}
}
接下来是限定符函数,它执行以下三项操作:
计数器功能会增加map中包含的计数,该计数由客户ID加上控制事件中包含的警报ID键控。 如果键尚不存在,则将键设置为1。
如果我们只需要触发未来事件数据的警报,那么我们到目前为止所概述的工作就足够了。但正如我们之前提到的,如果新创建的规则触发历史事件(已经通过系统的事件)的警报,则必须通知我们的客户。
在内部,我们将历史事件问题的解决方案称为bootstrapping。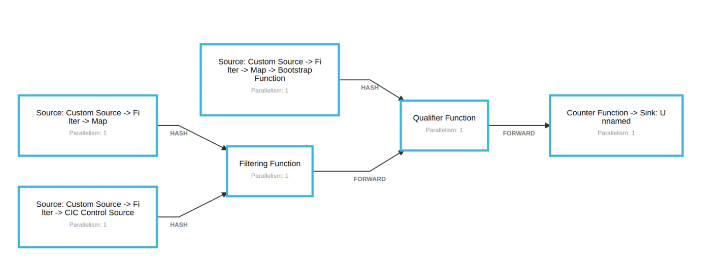
在上述不存在key的情况下,我们添加了一个额外的步骤。Counter函数将控制事件输出到新的Kafka主题。使用Kafka源在链中添加了一个新的“bootstrap”函数。它监听新主题。
当在引导函数中接收到引导请求控制事件时,该函数从文件中检索历史事件并将它们输出到流。流与实时流统一,并像以前一样进入限定符函数。 现在,计数反映了实时计数和历史计数。
我们刚刚完成的简化Flink工作实际上是四个Flink作业和几个数据库一起打破,所以让我们谈谈我们的生产部署还有什么其他内容。
显然,我们无法将所有历史生产数据存储在文本文件中,因此我们使用Apache Hadoop和Apache Hive来管理数据的长期存储。
有一个单独的Flink作业称为“摄取”,它将批量数据保存到Hive,并维护每个租户看到的最后一个时间戳列表。另一个名为“query”的Flink作业等待请求,当一个人进来时,它会向Ingest作业发送一个请求,以确保“查询”请求的时间戳持续存储到Hive。然后,它对Hive服务器执行查询并将其发送回查询请求者。
这两个Flink作业处理所有历史数据的存储和查询,但我们还有另外两个处理数据实际处理的作业。
这些工作几乎完全相同。但是,只处理历史数据而另一个处理实时数据。我们这样做是因为历史事件的处理可能相当昂贵。这是一项耗时的操作。 我们不希望它减慢或影响我们的实时警报的性能。
当实时数据作业处理其尚未计数的警报事件时,它会向历史数据作业发送请求,以针对该警报处理该租户的历史数据。完成后,历史数据作业将该请求的结果发送到实时数据作业。
因为事件的顺序对我们的警报很重要,所以我们实际上会“阻塞”实时事件,直到历史事件被处理完毕,但这个阻塞是人为的,并不会实际阻止事件的处理。当一个实时事件被引导并进入警报时,我们将该事件存储在一个不断扩展的缓冲区中。这显然存在内存风险,但我们使用带有MySQL的缓冲系统作为后端,以防止内存不足。历史数据作业完成警报处理后,实时数据作业处理缓冲的事件,使其准备好从此时开始处理实时事件。
感谢您的关注,我们希望您对我们的用例概述有所帮助。 同样,如果您想了解更多信息,可以在此处查看我们的Flink Forward演示文稿,并从此处的帖子中获取示例代码。
Beginner’s Guide to Quantitative Trading
本文中,我将介绍一个端到端量化交易系统的一些基本概念。这篇文章希望服务两类读者。一是希望获得一个量化交易员工作的人;二是希望创建自己“retail”算法交易业务的人。
量化交易是量化金融领域中一个十分复杂的领域。你需要付出大量的时间去学习必须的知识,从而通过面试或者构建自己的交易策略。而且它还需要有足够的编程经验,至少是MATLAB,R或者Python等编程语言中的一种。然而,随着交易频率的增加,技术面变得越来越相关。因此,熟悉C/C++是极为重要的。
一个量化交易系统包含四个主要的组件:
我们以如何识别交易策略作为开始。
###交易策略识别
所有的量化交易过程都始于最初的研究阶段。这个研究过程包含发现一个策略,看这个策略是否适合你正在运行的策略组合,后的测试策略所必须的任何数据,然后优化这个策略以期更好的回报和/或者更低的风险。如果做为一个“retail”交易员,你需要考虑你的资本需求以及交易成本对策略有多少影响。
与大众的看法相反,通过各种公共渠道找到盈利策略其实很简单。学术界定期公布理论交易结果(尽管大部分是交易费用总额)。定量金融博客将详细讨论策略。贸易杂志将概述基金使用的一些策略
你可能会问,为什么个人和公司都热衷于讨论他们的盈利战略,尤其是当他们知道其他人“拥挤的交易”可能会阻止该战略长期有效的时候。原因在于,他们将不会经常讨论他们已经得出的确切的参数和调整方法。这些优化是把一个相对平庸的战略变成一个高利润的战略的关键。事实上,创建自己独特策略的最佳方法之一是找到类似的方法,然后执行自己的优化过程。
以下是一些寻找策略想法的地方:
你将看到的许多策略将归入均值回归和趋势跟踪/动量的范畴。均值回归策略是试图利用“价格系列”(例如两个相关资产之间的价差)的长期均值存在的事实以及与此均值的短期偏差最终会恢复的事实。动量策略试图利用市场趋势搭便车来利用投资者心理和大型基金结构,市场趋势可以在一个方向上聚集动量,并跟随趋势直到它逆转。
量化交易的另一个非常重要的方面是交易策略的频率。低频交易(LFT)一般指持有资产超过一个交易日的任何策略。相应地,高频交易(HFT)通常指持有日内资产的策略。超高频交易(UHFT)是指在秒和毫秒量级持有资产的策略。作为一名零售商,只有对交易“技术堆栈”和订单动态有详细的了解后,HFT和UHFT当然是可能的。在这篇介绍性文章中,我们不会在很大程度上讨论这些方面。
一旦确定了一个或者一套策略,就需要在历史数据上进行盈利能力测试。这是回测的领域。
回溯测试的目的是提供证据,证明通过上述过程确定的策略在应用于历史数据和样本外数据时都是有利可图的。 这预示着战略将如何在“现实世界”中发挥作用。 但是,由于各种原因,回测不是成功的保证。 它可能是量化交易中最微妙的领域,因为它带来了许多偏差,必须尽可能仔细考虑和消除。 我们将讨论常见的偏差类型,包括前瞻偏差,生存偏差和优化偏差(也称为“数据窥探”偏差)。 回溯测试中的其他重要领域包括历史数据的可用性和清洁度,考虑实际交易成本以及确定鲁棒的回测平台。 我们将在下面的执行系统部分进一步讨论交易成本
一旦确定了战略,就必须获得历史数据,通过这些数据进行测试,或许可以进行改进。 所有资产类别中都有大量数据供应商。 它们的成本通常随着数据的质量,深度和及时性而变化。 开始量化交易者的传统起点(至少在零售层面)是使用雅虎财经的免费数据集。 我不会在这里过多地提供提供者,而是在处理历史数据集时我想集中讨论一般问题。
历史数据的主要问题包括准确性/清洁度,生存偏差以及对股息和股票分割等公司行为的调整
为了执行回测程序,必须使用软件平台。 您可以选择专用的backtest软件,例如Tradestation,数字平台(如Excel或MATLAB),或者使用Python或C ++等编程语言进行完全自定义实现。 我不会过多地关注Tradestation(或类似的),Excel或MATLAB,因为我相信创建一个完整的内部技术堆栈(由于下面列出的原因)。 这样做的好处之一是,即使使用非常先进的统计策略,也可以紧密集成回测软件和执行系统。 特别是对于HFT策略,使用自定义实现至关重要。
在回测系统时,必须能够量化它的性能。量化策略的“行业标准”指标是最大亏损和夏普比率。最大亏损表征了特定时间段(通常为年度)的账户净值曲线中最大的峰谷下降。这通常被称为百分比。由于许多统计因素,LFT策略往往比HFT策略具有更大的下降。历史回溯测试将显示过去的最大跌幅,这是该策略未来跌幅表现的良好指导。第二个衡量标准是夏普比率,启发式定义为超额收益的平均值除以超额收益的标准差。在这里,超额收益是指策略的回报高于预先确定的基准,例如标准普尔500指数或3个月国库券。请注意,年化回报不是通常使用的度量,因为它没有考虑策略的波动性(与夏普比率不同)。
通过良好的夏普和最小化的下降,一旦策略被回测并且被认为没有偏差(尽可能多的!),是构建执行系统的时候了。
执行系统是由策略生成的交易列表由代理发送和执行的手段。 尽管贸易生成可以是半自动化甚至是全自动化的,但执行机制可以是手动,半手动(即“一键”)或完全自动化。 对于LFT策略,手动和半手动技术很常见。 对于HFT策略,有必要创建一个完全自动化的执行机制,该机制通常与交易生成器紧密耦合(由于策略和技术的相互依赖)。
创建执行系统时的关键考虑因素是经纪人的接口,交易成本(包括佣金,滑点和差价)的最小化以及线上系统性能与回测性能的差异
有很多方法可以与经纪人联系。它们的范围从通过电话呼叫您的经纪人到全自动高性能应用程序编程接口(API)。理想情况下,您希望尽可能自动执行交易。这使您可以专注于进一步的研究,并允许您运行多种策略甚至更高频率的策略(事实上,如果没有自动执行,HFT基本上是不可能的)。上面概述的常用回溯测试软件,如MATLAB,Excel和Tradestation,适用于频率较低,策略较简单的软件。然而,有必要构建一个用高性能语言(如C ++)编写的内部执行系统,以便进行任何真正的HFT。作为一则轶事,在我曾经受雇的基金中,我们有一个10分钟的“交易循环”,我们每10分钟下载一次新的市场数据,然后在同一时间段内根据该信息执行交易。这是使用优化的Python脚本。对于接近分钟级或者秒级频率数据的任何事情,我相信C / C ++会更理想
在较大的基金中,优化执行通常不是量化交易者的领域。 然而,在较小的商店或高频交易公司中,交易员是执行者,因此通常需要更广泛的技能组合。 如果您希望受雇于基金,请记住这一点。 您的编程技能与统计学和计量经济学人才一样重要,甚至更重要!
落在执行旗下的另一个主要问题是交易成本最小化。 交易成本通常有三个组成部分:佣金(或税),即经纪人,交易所和证券交易委员会(或类似的政府监管机构)收取的费用; 滑点,这是您打算填写的订单与实际填写的订单之间的差异; 价差,即被交易证券的买入/卖出价格之间的差价。 注意,差价不是恒定的,并且取决于市场中当前的流动性(即买/卖订单的可用性)
交易成本可以在具有良好夏普比率的极其有利可图的策略和具有可怕的夏普比率的极其无利可图的策略之间产生差异。从回溯测试中正确预测交易成本可能是一项挑战。根据策略的频率,您需要访问历史交易数据,其中包括买入/卖出价格的价格数据。由于这些原因,在大型基金中整个团队都致力于优化执行系统。考虑一个基金需要卸载大量交易的情况(其中这样做的理由是多种多样的!)。通过将这么多股票“倾销”到市场上,它们将迅速压低价格并可能无法获得最佳执行。因此存在将“滴灌”订单推向市场的算法,尽管该基金存在滑点风险。此外,其他战略“捕食”这些必需品,并可以利用低效率。这是基金结构套利的领域
执行系统的最后一个主要问题是策略性能与回测性能的分歧。 这可能由于多种原因而发生。 在考虑回测时,我们已经深入讨论了前瞻偏差和优化偏差。 但是,某些策略无法在部署之前轻松测试这些偏差。 这主要发生在HFT中。 执行系统中可能存在错误以及交易策略本身没有出现在回溯测试中但是确实会出现在实际交易中。 在部署策略之后,市场可能会受到制度变更的影响。 新的监管环境,不断变化的投资者情绪和宏观经济现象都会导致市场行为的分歧,从而导致策略的盈利能力出现分歧。
量化交易难题的最后一部分是风险管理过程。 “风险”包括我们讨论过的所有先前的偏见。 它包括技术风险,例如位于相同交换机的服务器突然发生硬盘故障。 它包括经纪风险,例如经纪人破产(不像听起来那么疯狂,考虑到最近MF Global的恐慌!)。 简而言之,它涵盖了几乎所有可能干扰交易实施的内容,其中有许多来源。 全书都致力于量化策略的风险管理,所以我不会试图在这里阐明所有可能的风险来源。
风险管理还包括所谓的最优资本配置,这是投资组合理论的一个分支。 这是将资本分配给一系列不同策略以及这些策略中的交易的手段。 这是一个复杂的领域,依赖于一些非平凡的数学。 最佳资本分配和策略杠杆相关的行业标准称为凯利标准。 由于这是一篇介绍性文章,我将不再详述其计算方法。 凯利标准对回报的统计性质做出了一些假设,这在金融市场中并不常见,因此交易者在实施时往往保守。
风险管理的另一个关键组成部分是处理自己的心理状况。 有许多认知偏见可以渗透到交易中。 虽然如果策略是单独的,那么算法交易的问题就少了! 一个常见的偏差是损失厌恶(loss aversion),即失败的位置因为需要意识亏损的痛苦而没有关闭。 同样,利润也可能过早,因为担心失去已经获得的利润可能太大了。 另一种常见偏见称为新近偏差。 当交易者过分强调近期事件而不是长期事件时,这表明了这一点。 当然,还有一对经典的情绪偏见 - 恐惧和贪婪。 这些通常会导致杠杆率过低或过度杠杆化,这可能导致爆炸(即账户资产变为零或更差!)或利润减少
可以看出,量化交易是一个虽然非常有趣,但极其复杂的量化金融领域。 我在这篇文章中仅仅涉及了这个主题的表面,它已经变得相当长了! 那些我只给了一两句话的问题,都已经有一本书或者一篇论文去讨论。 因此,在申请量化基金交易工作之前,有必要进行大量的基础研究。 至少你需要大量的统计学和计量经济学背景,并且有很多实施经验,通过MATLAB,Python或R等编程语言。对于更高频率的更复杂的策略,你的技能很可能 包括Linux内核修改,C / C ++,汇编编程和网络延迟优化
如果您有兴趣尝试创建自己的算法交易策略,我的第一个建议是擅长编程。 我的偏好是尽可能多地构建数据抓取器,策略回溯测试器和执行系统。 如果你自己的资金在线上,你知道你已经完全测试了你的系统并意识到它的陷阱和特殊问题,你晚上睡不好吗? 将此外包给供应商,虽然可能在短期内节省时间,从长远来看代价可能非常昂贵
有状态函数和算子(operator)将数据存储在各个元素/事件的处理中,使状态成为任何类型的更精细操作的关键构建块。
比如:
Flink需要了解状态,以便使用检查点使状态容错,并允许流应用程序的保存点。
有关状态的知识还允许重新调整Flink应用程序,这意味着Flink负责跨并行实例重新分发状态。
Flink的可查询状态功能允许你在运行时从Flink外部访问状态。
在使用state时,阅读Flink的state backend(状态后端)可能也很有用。Flink提供了不同的状态后端,用于指定状态的存储方式和位置。State可以位于Java的堆上或堆外。根据您的状态后端,Flink还可以管理应用程序的状态,这意味着Flink处理内存管理(如果需要可能会溢出到磁盘)以允许应用程序保持非常大的状态。你可以在不更改应用程序逻辑的情况下配置状态后端。
stateFlink中有两种基本状态:Keyed State和Operator State.
Keyed State 和 operator stateKeyed StateKeyed Steate 永远跟key有关,只能作用到keyed stream上。
你可以把Keyed Stream理解为被分区或者共享的,每个key只有一个状态-分区的Operator State.每个keyed-state逻辑上被绑定到一个唯一的<parallel-instance,key>的组合上,并且因为每个key属于一个确切的keyed-operator的并行实例(parallel-instance),所以我们可以将其简单的成为<operator,key>`。
keyed-state进一步被组织为所谓的Key Groups.Key Groups是Flink重新分发Keyed State的原子单位(atomic unit);Key Groups数量与定义的最大并行度相等。在运行期间,每个keyed operator的并行实例(parallel instance)处理一个或者多个key group的keys。
operator state对Operator State(non-keyed state)来说,每个operator state被绑定到一个并行实例上。Kafka Connector是在Flink中使用Operator State的一个很好的示例。每个Kafka消费者的并行实例维护一个topic分区和偏移量(offset)的映射(map)作为它的operator state
当并行度改变时,Operator State接口支持在并行的operator实例间重新分发状态。可以有不同的方案来进行这种重新分发。
Raw and Managed State)Keyed State和Operator State以两种形式存在:managed和raw。
托管状态(Managed State):由Flink运行时控制的数据结构表示,例如内部哈希表或RocksDB。托管状态的例子有ValueState,ListState等。Flink的运行时对这些状态进行编码并将它们写入检查的(checkpoint)。
原始状态(Raw State): operator保存在自己数据结构中的状态。当执行写入检查点操作时(checkpointed),它们只会将一个字节序列写到到检查点(checkpoint)。Flink对状态的数据结构一无所知,只能看到原始字节。
所有的数据流都可以使用托管状态,但是原始状态只能在operator上使用。我们推荐使用托管状态(而不是原始状态),因为在使用托管状态时,Flink可以在并行度改变后自动重新分发状态,并且能够更好的进行内存管理。
注意 如果你需要对托管状态的序列化逻辑进行自定义,务必参考这里 来保证对未来的兼容性。Flink默认的序列化器不需要特殊处理。
managed keyed state)托管键控状态(managed keyed state)接口提供了对不同状态类型的访问,这些类型的作为方位都被限定在当前输入元素的键(key)上。这意味着这个类型的状态只能被用在键流(keyed stream)上,这些流可以由stream.keyBy(...)来创建。
支持的状态有:
ValueState<T>ListState<T>ReducingState<T>AggregatingState<IN, OUT>MapState<UK, UV>注意
key如果想获取状态的句柄,需要创建一个StateDesciptor。它保存了状态的名称(我们稍后会看到,您可以创建多个状态,并且它们必须具有唯一的名称以便您可以引用它们),以及状态所持有的值的类型,还可能有一个用户自定义的函数,如ReduceFunction。根据想要检索的状态类型,创建ValueStateDescriptor,ListStateDescriptor,ReducingStateDescriptor或者MapStateDescriptor.
因为State通过RuntimeContext来访问,所以只可能在rich function里使用。可以查看这里(简而言之就是rich function可以为我们提供除了普通function以外,还有:open, close, getRuntimeContext,和 setRuntimeContext四个函数,赋予我们做更多事情的能力)。在Rich fucntion里的RuntimeContext有以下访问对象的方法:
ValueState<T> getState(ValueStateDescriptor<T>)ReducingState<T> getReducingState(ReducingStateDescriptor<T>)ListState<T> getListState(ListStateDescriptor<T>)AggregatingState<IN, OUT> getAggregatingState(AggregatingState<IN, OUT>)FoldingState<T, ACC> getFoldingState(FoldingStateDescriptor<T, ACC>)MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)下面是FlatMapFunction的一个例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
Time-to-Live TTL)time-to-live可以在任意类型的keyed state上设置。如果一个状态设置了TTL,并且已经过期,那么被保存的值就会被清理。
所有的状态集合类型都支持per-entry TTL,也就是说list元素和map entries各自独立过期。
想要使用TTL,你需要首先构建一个StateTtlConfig配置对象。然后,可以通过传递配置在任何状态描述符中启用TTL功能。
例子:1
2
3
4
5
6
7
8
9
10
11
12import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
这里的配置有基础需要注意的:
newBuilder是强制的(mandatory),设置的是TTL值OnCreateAndWrite)StateTtlConfig.UpdateType.OnCreateAndWrite 只在创建和写的时候更新StateTtlConfig.UpdateType.OnReadAndWrite 读的时候也会更新NeverReturnExpired)StateTtlConfig.StateVisibility.NeverReturnExpired 过期值永远不会被返回StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp 如果还可用就返回注意
state backend会存储用户值最后一次修改的时间戳和值,这意味着开启这个特性会增加状态存储的消耗。Heap state backend在内存中存储一个额外的Java对象,其中包括一个用户状态对象的引用和一个初始(primitive)长整型。RocksDB state backend为每个存储值,列表条目(list entry)或(map entry)添加8个字节processing time的TTL。StateMigrationExceptioncheckpoint)或者保存点(savepoint)的一部分,而是Flink如何在当前运行的作业中对待它的一种方式。目前,只有在状态被显式读取的时候才会被清除,比如调用ValueState.getValue()
注意 这意味着默认情况下,未被读取的过期状态是不会被清除的,可能会导致状态不断增长。这可能在将来的版本中改变。
另外,你可以在获取完整状态快照的时候激活清理,这会减小状态的大小。当前实现下不会清除本地状态,但是从上一个快照恢复的情况下,它不会包括被清理的过期状态。它可以在StateTtlConfig中配置:1
2
3
4
5
6
7import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();
这个选项不适合在RocksDB state backend下的增量checkpointing
未来会添加更多策略,以便在后台自动清理过期状态
Managed Operator State)要想使用managed operator state,有状态函数要么实现CheckpointedFunction接口,要么实现ListCheckpointed<T extends Serializable>接口。
CheckpointedFunction接口CheckpointedFunction函数提供对具有不同重新分发方案的非键控(non-keyed)状态的访问。它需要实现线面两个方法:1
2
3void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;
当一个检查点需要被执行的时,snapshotState()会被调用。 每次用户自定义函数初始时会调用对应的initializeState(),即首次初始化函数时,或者当函数实际从早期检查点恢复时。鉴于此,initializeState()不仅是初始化不同类型状态的地方,而且还是包括状态恢复逻辑的地方。
当前,Flink支持list-style类型的managed operator state,状态应该是可序列化对象的列表(List),彼此独立,因此可以在调整大小时重新分发。换句话说,这些对象是可以重新分发非键控状态的最细粒度。根据状态访问方法,定义了以下重新分发方案:
Even-split redistribution) 每个operator返回一个状态元素的List,整个状态在逻辑上是所有列表的串联(concatenation)。在恢复(restore)/重新分发时,列表被分为与并行算子(parallel operator)数一样多的子列表。每个算子获得一个列表,这个列表可能为空,或者包含一个或更多列表。Union redistribution)。 每个operator返回一个状态元素的List,整个状态在逻辑上是所有列表的串联(concatenation)。在恢复(restore)/重新分发时,每个算子会获得一个完整的状态元素的列表。下面是一个例子,有状态函数SinkFunction使用CheckpointedFunction来缓冲在最终被发送到外界的元素。它演示了基本的均匀分布状态列表1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50public class BufferingSink
implements SinkFunction<Tuple2<String, Integer>>,
CheckpointedFunction {
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
public void invoke(Tuple2<String, Integer> value) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() == threshold) {
for (Tuple2<String, Integer> element: bufferedElements) {
// send it to the sink
}
bufferedElements.clear();
}
}
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
initializeState方法将FunctionInitializationContext作为参数。这用于初始化非键控状态“容器”。这些是ListState类型的容器,其中非键控状态对象将在检查点存储。
状态访问方法的命名约定包含其重新分发模式,后跟其状态结构。例如,要在还原时使用联合重新分发方案的列表状态,请使用getUnionListState(descriptor)访问该状态。如果方法名称不包含重新分发模式,例如getListState(descriptor),这意味着将使用基本的均匀分裂再分配(Even-split redistribution)方案。
在初始化容器之后,我们使用上下文的isRestored()方法来检查我们是否在失败后恢复。如果是,即我们正在恢复,则应用恢复逻辑。
如修改后的BufferingSink的代码所示,在状态初始化期间恢复的ListState保存在类变量bufferedElements中以供将来在`snapshotState()’中使用。在那里,ListState被清除了前一个检查点包含的所有对象,然后填充了我们想要检查点的新对象.
作为旁注,键控状态也可以在initializeState()'方法中初始化。这可以使用提供的FunctionInitializationContext`来完成
ListCheckpointed接口ListCheckpointed接口是CheckpointedFunction的一个更受限的变体,它仅支持在恢复时具有均匀分裂再分配(Even-split redistribution)方案的list-style的状态。它也要实现以下两个方法:1
2
3List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
void restoreState(List<T> state) throws Exception;
在snapshotState()里,算子(operator)应该将对象列表返回到检查点,并且restoreState()必须在恢复时处理这样的列表.如果状态不可重新分区,则始终可以在snapshotState()中返回Collections.singletonList(MY_STATE).
与其他operator相比,有状态的source需要更多的关注。为了使状态和输出集合的更新成为原子性的(在故障/恢复时Exactly-once语义所需),用户需要从source的上下文中获取锁(lock)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public static class CounterSource
extends RichParallelSourceFunction<Long>
implements ListCheckpointed<Long> {
/** current offset for exactly once semantics */
private Long offset;
/** flag for job cancellation */
private volatile boolean isRunning = true;
public void run(SourceContext<Long> ctx) {
final Object lock = ctx.getCheckpointLock();
while (isRunning) {
// output and state update are atomic
synchronized (lock) {
ctx.collect(offset);
offset += 1;
}
}
}
public void cancel() {
isRunning = false;
}
public List<Long> snapshotState(long checkpointId, long checkpointTimestamp) {
return Collections.singletonList(offset);
}
public void restoreState(List<Long> state) {
for (Long s : state)
offset = s;
}
}
当Flink完全确认检查点时,某些operator可能需要这些信息,以与外界通信。在这种情况下,请参阅org.apache.flink.runtime.state.CheckpointListener接口
1 | SELECT ... FROM TABLE_A |
要注意mysql/mariadb所属用户是否用权限写到目录或者文件
mysql -h my.db.com -u usrname--password=pass db_name -e 'SELECT foo FROM bar' > /tmp/myfile.txt