许多Apache Flink®用户正在构建警报或异常检测应用程序,ING和Mux是最近Flink Forward会议的两个例子。
今天,我们将重点介绍BetterCloud的工作,他们了解到,只有当新创建的警报应用于未来事件以及历史事件时,动态警报工具才真正对其客户有用。
在这篇客座文章中,我们将详细讨论BetterCloud如何使用Apache Flink为其警报提供动力,以及他们如何以高效的方式应对新创建的警报应用于历史事件数据的挑战。
这篇文章改编自2017年Flink Forward旧金山的BetterCloud会议。你可以在这里找到他们演讲的录音和幻灯片。
BetterCloud是一个多SaaS管理平台,可简化运营当今现代工作场所的IT专业人员的工作。 近年来,随着各种规模的公司依赖各种SaaS应用程序来运营其业务,这个世界变得更加复杂。
该平台作为IT的“任务控制”:用于管理公司内部使用的许多不同SaaS应用程序的单一控制台,例如Slack,G Suite,Salesforce和Dropbox。 BetterCloud允许其用户根据不同SaaS产品中的用户活动创建警报并执行自动策略。 例如,如果用户开始将其工作电子邮件转发到其个人Gmail帐户 - 提出潜在的安全问题 - IT或安全团队可以在BetterCloud中创建警报,自动阻止进一步转发,并向该个人发送通知,提醒他们公司政策。 BetterCloud还可以跨应用程序自动化复杂流程,例如入职或离职员工帐户(仅限G Suite,平均离职流程包含28个独特步骤)
BetterCloud提供了一个可供所有客户使用的“全局”警报库,它还使客户能够配置自定义警报。当客户创建BetterCloud警报时,它可以应用于未来事件以及历史事件。启用此自定义警报功能(可应用于未来事件和历史事件)为BetterCloud工程团队提出了一个非常重要的技术问题,在本文中,我们将详细介绍如何使用Apache Flink构建我们的警报系统来处理 未来和历史事件同时:
- 处理大规模数据: BetterCloud每天消耗数亿个事件
- 快速向客户发出警报: 触发事件发生后,即时警报对客户最有价值,这意味着低延迟至关重要
- 定期部署: 使用持续交付,我们需要尽快与客户验证新功能

基础学习:事件流模型和规则引擎
在警报项目开始时,我们的团队很快了解到事件流处理模型最适合我们的用例,具体而言,它比摄取(ingest)和查询模型更适合我们的警报应用程序。
由于大量的冗余处理,摄取和查询相对较慢且低效。我们已经提到低延迟对于像我们这样的警报系统很重要,而且这是摄取和查询模型无法做到的。最后,摄取和查询更多地关注状态而不是状态转换,而状态转换对我们来说很最重要。
每天由BetterCloud平台处理的数亿个事件已经通过Apache Kafka流式传输给我们(我们的数据提取团队在前期工作方面做得非常好),因此事件流处理模型对我们来说很简单
在选择流处理器时,BetterCloud不仅仅是凭空或者掷硬币选择Flink。我们根据一组评估标准评估了四种不同的流处理解决方案。我们选择选定了Flink,因为其充满活力的社区,商业支持的可用性以及实现exactly once处理的能力。
第二个关键设计决策:在流程的早期,我们认为规则引擎比硬编码规则更有价值。硬编码规则难以维护,缺乏灵活性,并且对于工程团队来说并不是很有趣。此外,我们的客户需要能够根据他们关心的事件自定义警报。
我们的团队已经将Avro或JSON作化为序列化格式的标准,因此我们选择了Jayway的JsonPath作为规则引擎。JsonPath对离散的JSON文档执行查询,它还提供了一种非常简单的方法来围绕查询包装非技术用户界面。在线上实际运行新查询之前,我们的用户也可以先测试新查询是否按预期工作。
JsonPath将文档解析为树,并使用熟悉的点表示法遍历树。它还提供索引和JavaScript运算符的子集(例如,数组的长度)。它支持的查询相当复杂。
结果是我们的最终用户可以在BetterCloud平台内创建自己的警报,并根据自定义事件的某些组合进行触发。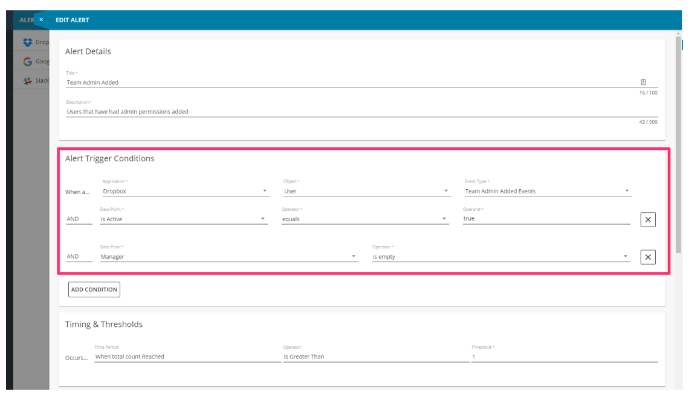
通过控制流添加规则
用户添加新警报规则后,将其作为控制事件提交。我们的团队非常自由地使用控制事件,以便我们的Flink工作动态(基本上说:“嘿,这是我们希望您看到的新事物”),并且当新事件通过实时事件流时,我们能够 根据新增的规则评估它们。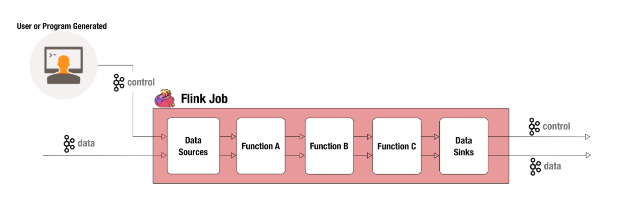
在我们的大部分Flink工作中,第一个功能是CoFlatMap的变体。当一起滚动时,我们最终得到2个Kafka源:一个用于控制事件,一个用于实时数据。两者都流入过滤功能,该功能维护由控制事件发送的警报配置。我们检查客户是否为他们创建的事件类型配置了任何警报,然后我们将该事件与所有可能匹配的警报相结合。
接下来,事件将转发到限定符函数,该函数负责对警报配置执行JsonPath评估。如果事件与警报配置匹配,则将其转发到计数器函数,然后将该事件发送到输出流。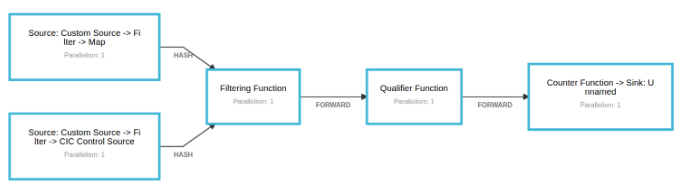
简单的Flink作业演示
现在,让我们来看看我们的一个Flink工作的简化版本。如果你想仔细看看我们在这篇文章中提到的代码,它可以在Github上找到。
首先,这是我们的每个事件类型的样子。客户事件(我们的实时事件流)具有客户ID和有效负载,它是JSON字符串。控制事件具有客户ID,警报ID以及许多其他字段,包括引导客户ID,我们稍后会介绍。 这在将新创建的规则应用于历史数据方面发挥了作用。1
2
3case class CustomerEvent(customerId: UUID, payload: String)
case class ControlEvent(customerId: UUID, alertId: UUID, alertName: String, alertDescription: String, threshold: Int, jsonPath: String, bootstrapCustomerId: UUID)
如前所述,我们有一个事件流源,它以客户ID为键,以确保在单个Flink任务管理器上维护单个客户的所有计数。您将看到我们过滤掉与模式不匹配的事件。1
2
3
4val eventStream = env.addSource(new FlinkKafkaConsumer09("events", new CustomerEventSchema(), properties))
.filter(x => x.isDefined)
.map(x => x.get)
.keyBy((ce: CustomerEvent) => { ce.customerId } )
还有一个控制流源:
1 | val controlStream = env.addSource(new FlinkKafkaConsumer09("controls", new ControlEventSchema(), properties)) |
BetterCloud中的一些规则是全局规则,这意味着它们可供所有客户使用。那些,我们向所有task manager广播如下:1
val globalControlStream = controlStream.select("global").broadcast
其他规则是特定于客户的,因此使用我们在实时事件流中所期望的相同客户ID进行键控。1
2val specificControlStream = controlStream.select("specific")
.keyBy((ce: ControlEvent) => { ce.customerId })
然后,我们将事件流连接到全局和特定控制流的联合:1
2val filterStream = globalControlStream.union(specificControlStream)
.connect(eventStream)
接下来,事件进入CoFlatMap。FlatMap 1将控件事件添加到本地状态的列表中。如果现有规则有更新,我们也可以在此处进行更改。FlatMap 2接收实时客户事件并检查是否存在与该客户ID匹配的任何规则配置。如果匹配,则将事件与所有匹配的控制事件一起输出为单个过滤事件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class FilterFunction() extends RichCoFlatMapFunction[ControlEvent, CustomerEvent, FilteredEvent] {
var configs = new mutable.ListBuffer[ControlEvent]()
override def flatMap1(value: ControlEvent, out: Collector[FilteredEvent]): Unit = {
configs = configs.filter(x => (x.customerId != value.customerId) && (x.alertId != value.alertId))
configs.append(value)
}
override def flatMap2(value: CustomerEvent, out: Collector[FilteredEvent]): Unit = {
val eventConfigs = configs.filter(x => (x.customerId == x.customerId) || (x.customerId == Constants.GLOBAL_CUSTOMER_ID))
if (eventConfigs.size > 0) {
out.collect(FilteredEvent(value, eventConfigs.toList))
}
}
}
接下来是限定符函数,它执行以下三项操作:
- 循环遍历筛选事件中的每个控件事件
- 针对实时事件评估控件事件上的JsonPath
- 向计数器函数发出0到n个包含实时事件和匹配控制事件的限定事件
计数器功能会增加map中包含的计数,该计数由客户ID加上控制事件中包含的警报ID键控。 如果键尚不存在,则将键设置为1。
处理历史数据
如果我们只需要触发未来事件数据的警报,那么我们到目前为止所概述的工作就足够了。但正如我们之前提到的,如果新创建的规则触发历史事件(已经通过系统的事件)的警报,则必须通知我们的客户。
在内部,我们将历史事件问题的解决方案称为bootstrapping。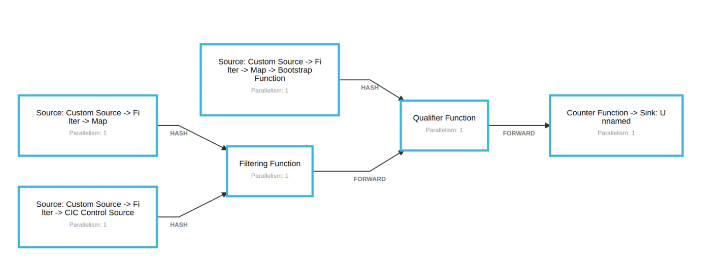
在上述不存在key的情况下,我们添加了一个额外的步骤。Counter函数将控制事件输出到新的Kafka主题。使用Kafka源在链中添加了一个新的“bootstrap”函数。它监听新主题。
当在引导函数中接收到引导请求控制事件时,该函数从文件中检索历史事件并将它们输出到流。流与实时流统一,并像以前一样进入限定符函数。 现在,计数反映了实时计数和历史计数。
稍微复杂的作业演示
我们刚刚完成的简化Flink工作实际上是四个Flink作业和几个数据库一起打破,所以让我们谈谈我们的生产部署还有什么其他内容。
显然,我们无法将所有历史生产数据存储在文本文件中,因此我们使用Apache Hadoop和Apache Hive来管理数据的长期存储。
有一个单独的Flink作业称为“摄取”,它将批量数据保存到Hive,并维护每个租户看到的最后一个时间戳列表。另一个名为“query”的Flink作业等待请求,当一个人进来时,它会向Ingest作业发送一个请求,以确保“查询”请求的时间戳持续存储到Hive。然后,它对Hive服务器执行查询并将其发送回查询请求者。
这两个Flink作业处理所有历史数据的存储和查询,但我们还有另外两个处理数据实际处理的作业。
这些工作几乎完全相同。但是,只处理历史数据而另一个处理实时数据。我们这样做是因为历史事件的处理可能相当昂贵。这是一项耗时的操作。 我们不希望它减慢或影响我们的实时警报的性能。
当实时数据作业处理其尚未计数的警报事件时,它会向历史数据作业发送请求,以针对该警报处理该租户的历史数据。完成后,历史数据作业将该请求的结果发送到实时数据作业。
因为事件的顺序对我们的警报很重要,所以我们实际上会“阻塞”实时事件,直到历史事件被处理完毕,但这个阻塞是人为的,并不会实际阻止事件的处理。当一个实时事件被引导并进入警报时,我们将该事件存储在一个不断扩展的缓冲区中。这显然存在内存风险,但我们使用带有MySQL的缓冲系统作为后端,以防止内存不足。历史数据作业完成警报处理后,实时数据作业处理缓冲的事件,使其准备好从此时开始处理实时事件。
结束
感谢您的关注,我们希望您对我们的用例概述有所帮助。 同样,如果您想了解更多信息,可以在此处查看我们的Flink Forward演示文稿,并从此处的帖子中获取示例代码。